Thank you very much for your positive feedback while I was busy with things like Windows 8 terminology, teaching at NYU, attending TKE and the ISO meetings in Madrid, and doing webinars. During one of the webinars, we didn’t get around to all questions. I will be addressing some of these here now.


Question: As you add terminology into your database, you might not remember that you have already entered some word that is a synonym. So, might you not end up with a different ID for 2 synonyms?
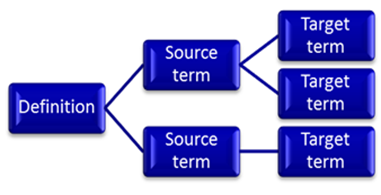
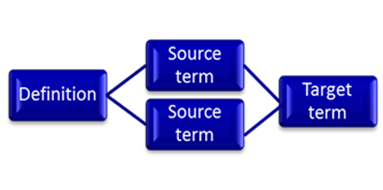
Answer: Yes, that is a scenario that is very common and that everyone setting up terminology entries is facing: We do our best to enter terms and names in canonical form in order to find them again and to avoid creating duplicates. So, we document, say, operating system and not Operating Systems, or we enter purge, and not to purge or purged in the database. Even though we were good about the form of our terms, we might not remember the meaning of all entries created and thus willy-nilly create doublettes in our database. Often times, we create them because we are not aware that one entry is a view onto a concept from one angle and a second entry might present the same concept from another angle, similar to these two pictures of the some flower.
Here are a few thoughts on what might help you avoid duplicate entries:
- Start out by specifying the subject field in your database. It will help you narrow down the concept for which you are about to create an entry. You might do a search on the subject field and see what concepts you defined at an earlier time. Sometimes that helps trigger your memory.
- As you are narrowing down the subject field and take a quick glance through some of the existing definitions, you might identify and recognize an existing concept as the one you are about to work on.
If you set up a doublette anyway—and it is bound to happen—you might find it later in one of the following ways and eradicate it:
- Export your database into a spreadsheet program and do a quick QA on your entries. In a spreadsheet, such as Excel, you can sort each column. If there are true doublettes, you might have started the definition with the same superordinate, which, if you sort the entries, get lined up next to each other.
- Maybe you don’t have time for QA, then I would simply wait until you notice while you are using your database and take care of it then. The damage in databases with lots of languages attached to a source language entry is bigger, but there are usually also more people working in the system, so errors are identified quickly. For the freelance translator, a doublette here and there is not as costly and it is also eliminated quickly once identified.
Developers of terminology management systems might eventually get to a point where maintenance functionality becomes part of the out-of-the-box program. At Microsoft, a colleague worked on an algorithm that helped us identify duplicates. The project was not completed when I left the corporate world, but a first test showed that the noise the program identified was not overwhelming. So, there is hope that with increasing demand for clean terminological and conceptual data such functionality becomes standard in off-the-shelf TMSs. In the meantime, stick with best practices when documenting your terms and names and use the database.